
Unraveling the Power of Supervised Learning
In the realm of artificial intelligence and machine learning, Supervised Learning stands as a foundational pillar, underpinning many of the groundbreaking technologies we encounter in our daily lives. In this comprehensive guide, we’ll delve deep into the world of Supervised Learning, exploring its fundamental concepts, real-world applications, and the remarkable impact it has on shaping our digital landscape.
what is unsupervised learning in machine learning
Table of Contents
- Introduction
- Understanding Supervised Learning
- 2.1 What is Supervised Learning?
- 2.2 Key Components of Supervised Learning
- How Supervised Learning Works
- 3.1 Training Data and Labels
- 3.2 The Learning Process
- Applications of Supervised Learning
- 4.1 Image Classification
- 4.2 Natural Language Processing
- 4.3 Medical Diagnosis
- Challenges and Considerations
- 5.1 Data Quality
- 5.2 Overfitting and Underfitting
- 5.3 Ethical Considerations
- Supervised Learning Algorithms
- 6.1 Linear Regression
- 6.2 Decision Trees
- 6.3 Support Vector Machines (SVM)
- Recent Advancements
- 7.1 Deep Learning and Neural Networks
- 7.2 Transfer Learning
- The Future of Supervised Learning
- Conclusion
- Frequently Asked Questions (FAQs)
Supervised Learning Introduction
Supervised Learning is a cornerstone of machine learning, driving numerous applications that make our lives easier and more efficient. In this article, we’ll explore the principles of Supervised Learning, its inner workings, and the vast array of fields it influences.
Supervised learning is a type of machine learning where the algorithm is trained on a labeled dataset. This means that the data is already classified and the algorithm learns to identify the patterns in the data that correspond to the different labels. Once the algorithm is trained, it can be used to predict the labels of new data points
types Supervised learning :
- Classification
- Regression
Classification
Classification algorithms are used to predict a categorical output variable, such as whether an email is spam or not, or whether a customer is likely to churn or not. Some popular classification algorithms include:
- Support vector machines (SVMs)
- Decision trees
- Logistic regression
- K-nearest neighbors
- Random forests
Regression
Regression algorithms are used to predict a continuous output variable, such as the price of a house or the temperature on a given day. Some popular regression algorithms include:
- Linear regression
- Polynomial regression
- Ridge regression
- Lasso regression
- Random forests
Both classification and regression algorithms are trained on a labeled dataset, which means that each input sample has a corresponding output value. The algorithm learns to map the input samples to the output values, and then uses this knowledge to make predictions on new data.
Supervised learning algorithms are widely used in a variety of applications:
- Fraud detection
- Medical diagnosis
- Customer relationship management (CRM)
- Product recommendation systems
- Financial forecasting
- Natural language processing (NLP)
- Image recognition
Understanding Supervised Learning
2.1 What is Supervised Learning?
Supervised Learning is a machine learning paradigm where an algorithm learns from labeled training data to make predictions or decisions without human intervention. It involves training a model on known inputs and their corresponding correct outputs, allowing the model to generalize and make accurate predictions on new, unseen data.
2.2 Key Components of Supervised Learning
Supervised Learning comprises two main components: the training data, which includes the input features, and the labels, which are the correct outputs or target values. The model’s goal is to learn the mapping from inputs to outputs.
How Supervised Learning Works
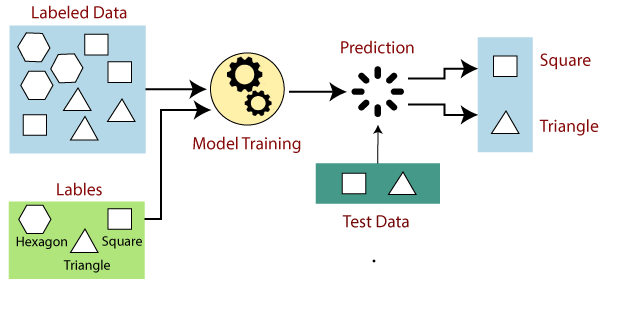
3.1 Training Data and Labels
In Supervised Learning, the training data consists of input examples paired with their correct labels. The model uses this data to learn patterns and relationships, enabling it to make predictions.
3.2 The Learning Process
The learning process in Supervised Learning involves adjusting the model’s parameters to minimize the difference between its predictions and the true labels. This optimization process continues until the model’s performance is satisfactory.
Sure,
- Collect a labeled dataset: This is a dataset where each data point has a known output. For example, a dataset of images of cats and dogs, where each image is labeled as either “cat” or “dog”.
- Choose a supervised learning algorithm: There are many different supervised learning algorithms, such as logistic regression, support vector machines, and decision trees. Each algorithm has its own strengths and weaknesses, so it is important to choose the right one for your problem.
- Train the algorithm: The algorithm learns to predict the output of new data points based on the labeled dataset.
- Evaluate the algorithm: Once the algorithm is trained, it is important to evaluate its performance on a held-out test dataset. This dataset should not be used to train the algorithm, as this would lead to overfitting.
- Deploy the algorithm: Once the algorithm is evaluated and its performance is satisfactory, it can be deployed to production. This means that it can be used to predict the output of new data points that it has never seen before.
Supervised learning algorithms can be broadly divided into two categories:
- Discriminative algorithms: These algorithms learn to distinguish between different classes of data points. Examples of discriminative algorithms include logistic regression, support vector machines, and decision trees.
- Generative algorithms: These algorithms learn to generate new data points that are similar to the training data. Examples of generative algorithms include Naive Bayes, Gaussian mixture models, and deep learning models.
Supervised learning algorithms are trained using a two-step process:
- Training: The algorithm is trained on a labeled dataset.
- Evaluation: The algorithm is evaluated on a held-out test dataset. The test dataset should not be used to train the algorithm, as this would lead to overfitting.
Overfitting occurs when the algorithm learns the training data too well and is unable to generalize to new data. To prevent overfitting, techniques such as regularization and cross-validation can be used.
Supervised learning is a powerful machine learning technique that can be used to solve a wide variety of problems. However, it is important to note that supervised learning algorithms require labeled data, which can be expensive and time-consuming to collect.
examples of supervised learning in the real world:
- Spam filters: Spam filters use supervised learning to classify emails as spam or not spam. The algorithm is trained on a labeled dataset of emails, where the emails have already been classified as spam or not spam. Once the algorithm is trained, it can be used to classify new emails.
- Product recommendation systems: Product recommendation systems use supervised learning to recommend products to users. The algorithm is trained on a labeled dataset of user interactions with products, such as ratings and purchases. Once the algorithm is trained, it can be used to recommend new products to users based on their past interactions.
- Fraud detection systems: Fraud detection systems use supervised learning to detect fraudulent transactions. The algorithm is trained on a labeled dataset of fraudulent and non-fraudulent transactions. Once the algorithm is trained, it can be used to flag new transactions as potentially fraudulen
Applications of Supervised Learning
4.1 Image Classification
Supervised Learning is instrumental in image classification tasks, enabling systems to classify images into predefined categories. Applications include facial recognition and autonomous vehicle perception.
4.2 Natural Language Processing
In the realm of natural language processing, Supervised Learning algorithms are used for sentiment analysis, language translation, and chatbot responses, making human-computer communication more seamless.
4.3 Medical Diagnosis
Supervised Learning plays a pivotal role in medical diagnosis, assisting doctors in identifying diseases and making accurate predictions based on patient data and medical images.
Challenges and Considerations
5.1 Data Quality
The quality of training data is critical. Noisy or biased data can lead to inaccurate predictions. Data preprocessing and cleaning are essential to ensure high-quality training data.
5.2 Overfitting and Underfitting
Overfitting occurs when a model learns the training data too well but struggles with new data. Underfitting, on the other hand, indicates that the model is too simplistic. Balancing these concerns is a key challenge.
5.3 Ethical Considerations
As Supervised Learning is applied in various domains, ethical considerations regarding privacy, bias, and accountability come to the forefront. Ensuring responsible AI usage is imperative.
Supervised Learning Algorithms
6.1 Linear Regression
Linear Regression is a foundational algorithm for regression tasks, where the goal is to predict a continuous numerical value. It models the relationship between the input features and the target variable.
6.2 Decision Trees
Decision Trees are versatile and interpretable models that can handle both classification and regression tasks. They make decisions by recursively splitting data based on features.
6.3 Support Vector Machines (SVM)
SVMs are powerful classifiers that aim to find the optimal hyperplane to separate data into distinct categories. They are used in both binary and multiclass classification problems.
Supervised Learning Advancements
7.1 Deep Learning and Neural Networks
Deep Learning, a subfield of Supervised Learning, has witnessed remarkable advancements, particularly in image and speech recognition, thanks to neural networks with multiple layers.
7.2 Transfer Learning
Transfer Learning allows models trained on one task to be fine-tuned for another. This approach has led to significant efficiency gains, especially in deep learning models.
The Future of Supervised Learning
Supervised Learning continues to evolve, paving the way for innovations in diverse domains. As data collection and computing power grow, we can expect increasingly accurate and robust models.
- More powerful algorithms: Researchers are constantly developing new supervised learning algorithms that are more accurate and efficient. For example, deep learning algorithms have achieved state-of-the-art results on a variety of tasks, including image recognition, natural language processing, and machine translation.
- More data: As we collect more data, supervised learning algorithms will be able to learn more complex patterns and make more accurate predictions. For example, the availability of large datasets of medical images has enabled the development of supervised learning algorithms that can diagnose diseases with high accuracy.
- More applications: Supervised learning algorithms are already being used in a wide variety of applications, and this trend is only going to continue in the future. For example, supervised learning algorithms are being used to develop self-driving cars, improve fraud detection systems, and personalize the user experience on websites and apps.
Conclusion
Supervised Learning is the bedrock of modern AI, powering technologies that enhance our lives in numerous ways. Its ability to learn from labeled data and make predictions has transformed industries and will continue to do so in the future.
Frequently Asked Questions (FAQs)
- What is the fundamental concept of Supervised Learning?
- Supervised Learning involves training a model with labeled data to make predictions or decisions autonomously.
- How does Supervised Learning differ from Unsupervised Learning?
- In Supervised Learning, the model is trained on labeled data with known outcomes, while Unsupervised Learning works with unlabeled data to discover patterns.
- What are some common applications of Supervised Learning in everyday life?
- Applications include recommendation systems, speech recognition, email filtering, and more.
- How can we address bias and fairness issues in Supervised Learning models?
- Ensuring diverse and representative training data and using fair algorithms are key steps to mitigate bias.
- What should aspiring data scientists and machine learning enthusiasts do to get started with Supervised Learning?
- Begin by learning programming languages like Python and studying machine learning libraries such as scikit-learn and TensorFlow.
best product
amazon basics True Wireless in-Ear Earbuds
Redmi 12 5G Jade Black 4GB RAM 128GB ROM
more realete blog
what is AI // क्या है ai //type of ai
Deep Learning//WHAT IS DEEP LEARNING
Reinforcement learning- (RL)-What is RL in reinforcement?-introduction

